Comment l’Intelligence Artificielle va rendre le Web plus accessible
Cet article à été publié par Abhinav Suri, un chef de projet dans les techno-biologies: Selon l’Organisation mondiale de la santé, environ 285 millions de personnes souffrent de déficience visuelle dans le monde. Rien qu’aux États-Unis, 8,1 millions d’internautes ont une déficience visuelle. Alors voiçi comment l’Intelligence Artificielle va aider toutes ces personnes à profiter de la révolution digitale…
Ce que la plupart des personnes non handicapées considèrent comme étant « l’Internet », est un endroit plein de texte, d’images, de vidéos, etc., qui est quelque chose de complètement différent pour les malvoyants. Les lecteurs d’écrans qui sont des outils qui peuvent lire du texte et des métadonnées sur une page Web, restent très limités et ne peuvent exposer qu’une partie d’une page Web, à savoir le texte d’un site web. Alors que certains développeurs prennent le temps de parcourir leurs sites et d’ajouter des légendes descriptives à leurs images pour les utilisateurs malvoyants, la grande majorité des programmeurs ne prennent pas le temps de faire cette tâche certes fastidieuse.
Un outil pour aider les personnes malvoyantes à « Voir » l’Internet avec la puissance de l’IA a été crée. Il s’appelle Auto Alt Text et c’est une extension chrome qui permet aux utilisateurs de faire un clic droit et d’obtenir une description de la scène dans une image. Ceci est le premier outil qui permet d’effectuer une telle chose. Cet article relate fidèlement l’expérience du créateur de ce logiciel hors du commun.
Regardez la vidéo ci-dessous pour voir comment cela fonctionne et téléchargez-la pour l’essayer!
<iframe width= »560″ height= »315″ src= »https://www.youtube.com/embed/c1S4iB360m8″ frameborder= »0″ allowfullscreen></iframe>
Pourquoi j’ai créé Auto Alt Text
J’avais l’habitude d’être un de ces développeurs qui ne prenait pas le temps d’ajouter des descriptions aux images sur les pages web. Pour moi, l’accessibilité a toujours été une seconde pensée jusqu’à ce que je reçoive un email d’un utilisateur d’un de mes projets et voici ce qu’il disait :
Salut Abhinav, j’ai trouvé votre projet flask base et je pense que cela va certainement être un bon choix pour mon prochain projet. Merci d’avoir travaillé dessus. Je voulais juste vous faire savoir que vous devriez envisager de mettre des descriptions sur vos images. Je suis légérement aveugle et j’ai eu du mal à en distinguer le contenu.
À ce moment-là, mon processus de développement avait mis l’accessibilité au plus bas de la liste des priorités. Cet e-mail était un rappel à l’ordre pour moi. De nombreuses personnes sur Internet ont besoin de fonctionnalités d’accessibilité pour comprendre l’intention initiale des sites Web, des applications, des projets, etc.
En effet, selon WebAIM (Centre pour les personnes handicapées de l’Université d’État de l’Utah):
Le Web est rempli d’images qui ont du texte alternatif manquant, incorrect ou pauvre.
L’intelligence artificielle à la rescousse
Il existe de nombreuses façons de légender les images; cependant, la plupart ont quelques inconvénients en commun:
- Ils ne sont pas réactifs et prennent beaucoup de temps pour retourner une légende.
- Ils sont semi-automatisés (c’est-à-dire qu’ils s’appuient sur des humains pour légender manuellement des images à la demande).
- Ils sont chers à créer et à maintenir.
En créant un réseau neuronal, tous ces problèmes peuvent être résolus. J’ai récemment commencé à plonger dans l’apprentissage automatique et l’intelligence artificielle lorsque je suis tombé sur Tensorflow, une librairie open source pour l’apprentissage automatique. Tensorflow permet aux développeurs d’architecturer des modèles robustes qui peuvent être utilisés pour effectuer diverses tâches, de la détection d’objet à la reconnaissance d’image.
En faisant un peu plus de recherches, j’ai rencontré un article de Vinyals et al intitulé «Show and Tell: Leçons tirées du défi du sous-titrage d’images MSCOCO 2015». Ces chercheurs ont créé un réseau neuronal profond pour décrire le contenu de l’image de manière sémantique.
Quelques exemples de im2txt en action:

Détails techniques du im2txt
La mécanique du modèle est assez détaillée, mais fondamentalement c’est un schéma « codeur-décodeur ». Tout d’abord, l’image est passée à travers un réseau neuronal convolutif profond appelé Inception v3, un classificateur d’images. Ensuite, l’image codée est alimentée par un LSTM qui est un type de réseau neuronal spécialisé dans la modélisation des séquences / informations sensibles au temps. Le LSTM travaille ensuite à travers un vocabulaire défini et construit une phrase pour décrire l’image. Pour ce faire, il prend la vraisemblance que chaque mot de cet ensemble fait apparaitre en premier dans la phrase, puis calcule la distribution de probabilité du second mot la plus probable étant donné la distribution de probabilité du premier mot et ainsi de suite jusqu’à ce que le caractère le plus probable soit un point indiquant la fin de la légende.
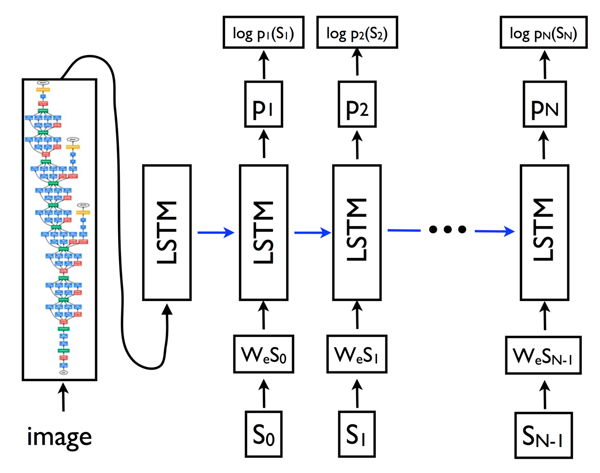
Selon le repository Github, le temps d’apprentissage de ce réseau neuronal était d’environ 1 à 2 semaines sur un GPU Tesla k20m (probablement beaucoup plus pour un processeur standard sur un ordinateur portable). Heureusement, un membre de la communauté tensorflow a fourni un modèle qualifié pour le téléchargement public.
Autres problèmes rencontrés
Lors de l’exécution du modèle, j’ai réussi à faire fonctionner avec Bazel, un outil qui sert à pré-packager des modèles Tensorflow dans des scripts exécutables (entre autres choses). Cependant, il m’a fallu près de 15 secondes pour obtenir un résultat d’une seule image lors de l’exécution sur la ligne de commande ! La seule façon de résoudre ce problème de lenteur était de garder le graph Tensorflow en mémoire, mais cela nécessiterait de garder l’application en place 24/7. Je prévoyais de mettre ce modèle sur des serveur Amazon AWS Elasticbeanstalk, où le temps de calcul est calculé au prorata de l’heure et que le maintien d’une application tout le temps n’était pas idéal (ce qui se traduisait par la situation n° 3 des inconvénients des logiciels de sous-titrage). J’ai donc décidé de passer à Amazon AWS Lamdba pour héberger le tout.
Lambda est un service qui fournit un hebergement sans serveur pour un coût incroyablement bas. En outre, le coût est calculé sur la base des secondes d’utilisation lorsqu’il est activement utilisé. La façon dont Lambda fonctionne est simple: une fois que votre application reçoit une demande d’un utilisateur, Lambda active une image de votre application, produit une réponse puis désactive cette image. Si vous avez plusieurs demandes simultanées, il ne fait qu’accumuler plus d’instances. En outre, votre application sera activée tant qu’il y a plusieurs demandes dans l’heure. Ce service a été un bon ajustement pour mon cas d’utilisation.
Le problème avec Lambda était que je devais créer une API pour le modèle im2txt. Mais Lamdba a des contraintes de mémoire sur l’application qui peuvent être chargées en tant que fonction. Lors du téléchargement d’un fichier zip contenant tout le code de votre application, y compris les dépendances, le fichier final ne peut pas dépasser 250 Mo. Cette limite était un problème puisque la taille du modèle im2txt était supérieure à 180 Mo et que les dépendances à exécuter dépassaient 350 Mo. J’ai essayé de contourner ce problème en téléchargeant certaines parties dans une instance S3 et en téléchargeant dans mon exécution de l’instance lambda quand il était actif; Cependant, la limite de taille de stockage totale sur lambda est de 512 Mo, ce qui était largement dépassé (environ 530 Mo).
Pour réduire la taille finale de mon projet, j’ai reconfiguré im2txt pour accepter un modèle réduit contenant uniquement le point de contrôle et aucune métadonnée étrangère. Cette suppression a réduit ma taille de modèle à 120 Mo. J’ai ensuite découvert lambda-packs qui contenait une version minimisée de toutes les dépendances, bien qu’avec une version antérieure de Python et Tensorflow. Après avoir traversé le douloureux processus de rétrogradation de la syntaxe python 3.6 et du code tensorflow 1.2, j’ai finalement eu un paquet qui était environ 480 Mo au total, juste en dessous de la limite de 512 Mo.
Pour garder les temps de réponse rapides, j’ai créé une fonction CloudWatch pour garder l’instance Lambda «chaude» et l’application active. J’ai ajouté quelques fonctions d’aide pour manipuler des images non au format JPG et j’ai finalement eu une API fonctionelle. Toutes ces réductions ont conduit à un temps de réponse rapide de moins de 5 secondes dans la plupart des cas !

De plus, Lambda est incroyablement bon marché, au prix actuel, je peux analyser 60 952 images gratuitement mensuellement et toute image supplémentaire pour $ 0.0001094 (soit environ $ 6.67 pour les 60.952 images suivantes).
Plus de détails sur l’API peuvent être trouvés dans le référentiel: https://github.com/abhisuri97/auto-alt-text-lambda-api
Tout ce qui restait à faire c’était de l’empaqueter dans une extension chrome pour faciliter l’utilisation pour l’utilisateur final, ce qui n’était pas une tâche trop difficile (puisqu’il s’agissait juste d’une simple requête AJAX à mon point de terminaison API).

Résultats
Im2txt fonctionne bien sur des images de personnes, de paysages, etc., à condition que ces objets soient présents dans le jeu de données COCO (Common Objects in Context).

Ce modèle limite quelque peu la portée de ce qui peut être sous-titré; cependant, il couvre une majorité d’images vues sur des sites de médias sociaux tels que Facebook et Reddit.
Cependant, il échoue souvent de légender les images contenant du texte, car le jeu de données COCO ne contient aucune image de ce type. J’ai essayé d’utiliser Tesseract pour accomplir cette tâche; cependant, les résultats étaient trop imprécis et trop longs à produire (plus de 10 secondes). Je travaille actuellement sur une mise en œuvre de l’article de Wang et al. Dans Tensorflow pour aider à accomplir cette tâche.
Conclusion
Bien qu’il y ait une nouvelle histoire sur les merveilles de l’IA chaque semaine, il est important de prendre du recul et de voir comment ces outils peuvent être utilisés en dehors du cadre de recherche et comment ces résultats peuvent aider les gens à travers le monde. Dans l’ensemble, j’ai adoré faire cette plongée dans Tensorflow avec im2txt et être capable d’appliquer ce que j’ai appris à un problème réel. Avec un peu de chance, cet outil sera le premier d’un grand nombre à aider les personnes malvoyantes à avoir une meilleure expérience digitale.